
Introduction
Last week, my team was forwarded this screenshot from Grafana, which showed a sudden spike in memory usage of our processing service:
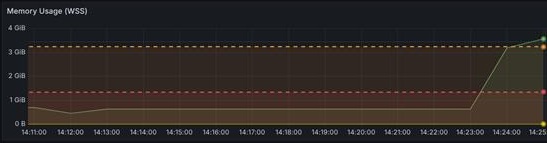
We were asked to look into it, as the traces were unclear and the spike was causing stability issues in production. Fortunately, the logs accurately pointed us to the document involved in the spike. Unfortunately, it was just a single-page PDF document that weighed only around ~1MB, so at first glance, we couldn’t draw any conclusions from it.
One of my team members, started investigating the issue and quickly found that the spike was caused by the ZBar library, which we use to decode QR codes in our service.
It was unclear to us at first why ZBar consumed so much memory, so I decided to get cracking.
Understanding the current processing
So, first we need to understand what exactly is the state of the current QR code processing. Since ZBar does not support processing PDF documents directly, we first convert the PDF to an image using the pdftoppm command line utility (part of the Poppler library). Then, we use ZBar to try and detect the QR code in the image. Easy and straightforward; and it worked well for us so far.
Preparing the test document
As the original document that caused the spike is confidential, I downloaded a sample PDF invoice from the Internet, stuck a QR code on it, printed it out and scanned to a PDF (to at least try to replicate the process the customer used). Here’s how the document looks like:

The actual PDF file that I created weighs 1.74MB, which is slightly larger than the original document that caused the spike.
What is this resolution?
Let’s look at the memory footprint of this processing with a simple benchmarking script using tracemalloc.
And this is the output of the benchmarking script:
$ python ./zbar_process.py testdata.pdf
Starting PDF processing for testdata.pdf at 500 DPI...
PDF converted to 1 images.
Processing image 1/1
- Found barcode: http://kamilmarut.com
- Current memory usage: 0.78MB
- Peak memory usage: 46.81MB
--------------------
Processing finished in 2.25 seconds.Wow! The peak memory is nearly 27 times the size of the original PDF document! We have successfully read out the QR code from the document, but at what cost? The memory footprint is quite high, so let’s try to understand why.
The first clue is the one that’s already printed in the output: we have converted the PDF to an image at 500 DPI. That is most likely unnecessarily high and will definitely eat up a lot of memory! Since this is the value that was set on production, we should try to go down with it.
$ python ./zbar_process.py CCI10072025.pdf --resolution=300
Starting PDF processing for CCI10072025.pdf at 300 DPI...
PDF converted to 1 images.
Processing image 1/1
- Found barcode: http://kamilmarut.com
- Current memory usage: 0.78MB
- Peak memory usage: 17.35MB
--------------------
Processing finished in 1.14 seconds.
$ python ./zbar_process.py CCI10072025.pdf --resolution=100
Starting PDF processing for CCI10072025.pdf at 100 DPI...
PDF converted to 1 images.
Processing image 1/1
- Found barcode: http://kamilmarut.com
- Current memory usage: 0.78MB
- Peak memory usage: 2.62MB
--------------------
Processing finished in 0.41 seconds.
$ python ./zbar_process.py CCI10072025.pdf --resolution=80
Starting PDF processing for CCI10072025.pdf at 80 DPI...
PDF converted to 1 images.
Processing image 1/1
- Found barcode: http://kamilmarut.com
- Current memory usage: 0.78MB
- Peak memory usage: 1.96MB
--------------------
Processing finished in 0.38 seconds.
$ python ./zbar_process.py CCI10072025.pdf --resolution=50
Starting PDF processing for CCI10072025.pdf at 50 DPI...
PDF converted to 1 images.
Processing image 1/1
- No barcodes found.
- Current memory usage: 0.78MB
- Peak memory usage: 1.24MB
--------------------
Processing finished in 0.35 seconds.As we can see, the peak memory usage drops significantly as we lower the DPI value. At 50 DPI, we are not able to detect the QR code anymore, but at 80 DPI, we are still able to read it and the peak memory usage is only 1.96MB, which is much more reasonable. My further experiments show that 80 unfortunately is too low a value, as even slightly smaller QR codes are not picked up anymore. Depending on your use case, the DPI of 100-150 could be reasonable, but for us, the sweet spot turned out to be somewhere around 220 DPI. Which still saves us about 1.5 second of processing time and nearly 6 times less memory usage compared to the original 500 DPI setting.
What about pre-processing?
Changing the resolution was a great fix and a quick hotfix to change the resolution in production definitely saved us on some computing costs, but why not try to optimize even further? There are 2 optimizations that immediately come to mind:
- scale the image down
- convert the image to grayscale
Since grayscaling the image turned out to be a very non-invasive change, I decided to bundle it together with the resizing in a single parameter called --optimize. Please notice that I use the Pillow library to handle the pre-processing, but the pdftoppm utility does support both of those operations as well with the -scale-to and -gray parameters, so you should most likely prefer them. I just did this simply because I did not know about those parameters at the time of writing the script and I’m quite proficient with Pillow.
Let’s try to run the script with the --optimize parameter on the original 500 DPI image:
$ python ./zbar_process.py CCI10072025.pdf --optimize
Starting PDF processing for CCI10072025.pdf at 500 DPI...
PDF converted to 1 images.
Processing image 1/1
- Resizing image from 4015x5727 to 1024x768
- Converting to grayscale
- Found barcode: http://kamilmarut.com
- Current memory usage: 0.78MB
- Peak memory usage: 2.36MB
--------------------
Processing finished in 1.88 seconds.This is great! This pre-processing alone had bigger impact on the memory usage than the resolution change! The processing time is also slightly lower, although it appears changing the density of the image has had a much bigger impact here.
Now, let’s try to run pre-processing on the image with the resolution set to 100 DPI:
$ python ./zbar_process.py CCI10072025.pdf --resolution=100 --optimize
Starting PDF processing for CCI10072025.pdf at 100 DPI...
PDF converted to 1 images.
Processing image 1/1
- Resizing image from 803x1146 to 717x1024
- Converting to grayscale
- Found barcode: http://kamilmarut.com
- Current memory usage: 0.78MB
- Peak memory usage: 2.25MB
--------------------
Processing finished in 0.43 seconds.There’s an extra overhead of .02 seconds in processing time compared to just the resolution change due to the extra pre-processing, but the peak memory usage is reduced even further. If you’re optimizing for memory usage, you should definitely consider this pre-processing step.
Summary
In the end, we decided to only go with the DPI parameter change and the grayscaling in a pre-processing step, as we didn’t want to risk breaking processing for documents that we don’t have in our test suite. Remember, when tweaking parameters such as image resolution and quality, the clean-room strategy gives you an idea of what you can save, but you should always test on a representative sample of your production data.
And for anybody curious, this is as low as I could go with the optimizations before ZBar stopped detecting the QR code:
$ python ./zbar_process.py CCI10072025.pdf --resolution=54 --optimize --save-image
Starting PDF processing for CCI10072025.pdf at 54 DPI...
PDF converted to 1 images.
Processing image 1/1
- Converting to grayscale
- Saving processed image to CCI10072025.jpg
- Found barcode: http://kamilmarut.com
- Current memory usage: 0.78MB
- Peak memory usage: 1.32MB
--------------------
Processing finished in 0.36 seconds.And this is how the final image looks like:

Sure, it’s small and there are visible artifacts, but still quite readable if you ask me - I don’t know why ZBar’s complaining!